Startseite › Produkte › Qlik Replicate
Qlik Replicate
Datenreplikation unabhängig vom Ort mit Qlik Replicate™
In den heutigen Unternehmen gibt es viele Quell- und Zielsysteme. Daten müssen repliziert werden, damit aussagekräftige Ergebnisse zustande kommen. Mit Qlik Replicate (ehemals Attunity Replicate) können Daten systemübergreifend erfasst, repliziert und gestreamt werden. Dabei arbeitet die Lösung mit geringster Belastung für das Quellsystem. Es ist egal wo die Daten liegen, On-Premise oder in der Cloud, Qlik Replicate synchronisiert die Systeme und die Daten werden einfach, sicher und effizient bewegt, ohne das operative Geschäft zu beeinträchtigen. Qlik Replicate bietet die Möglichkeit Daten in die Cloud migrieren, Aktualisierungen für einen Stream bereitstellen oder einen Data Lake kontinuierlich mit Daten versorgen. Mit Qlik Replicate stellen Sie eine universelle Datenverfügbarkeit her.
Daten aus allen wichtigen Datenbanken, Data Warehouses und Hadoop lassen sich mit Qlik Replicate systemübergreifend replizieren, synchronisieren, verteilen, konsolidieren und erfassen – On Premises und in der Cloud.
Qlik Replicate reduziert die Dauer des nächtlichen Batch-Ladevorgangs deutlich verkürzen,
Ein Kreditservice-Anbieter konnte 14 Millionen Änderungen aus der Quelle innerhalb von 30 Sekunden in das Ziel übertragen.
Ressourcenschonend durch Change Data Capture (CDC) Technologie
Als Change Data Capture (CDC) wird eine Methode bezeichnet, bei mit der Datenänderungen in einem operativen System aus Transaction Logs ermittelt werden. Bei Änderungen werden diese Daten sofort in das Zielsystem repliziert. Qlik Replicate verwendet dazu eine moderne Echtzeit-CDC Technologie für eine breite Anzahl von Systemen. Dabei können Daten aus Oracle, MS SQL Server, Teradata, Hadoop, SAP, AWS, Azure, Google Cloud und vielen weiteren Systemen mit einer niedrigen Latenz und hohem Durchsatz übertragen werden.
Beschleunigung von Migrations- und Analytics-Projekten
Durch eine webbasierte Konsole ist die Konfigurierung, die Kontrolle und das Monitoring aller Replikationsprozesse einfach und übersichtlich. Es wird für die Software kein tiefes Verständnis für Coding benötigt. Viele Prozesse können automatisiert werden. Zum Beispiel wird in der Zieldatenbank das Schema auf Basis der Metadaten des Quellsystems automatisch aufgebaut. Veränderungen im Quellsystem können automatisch auf das Zielsystem übertragen werden.
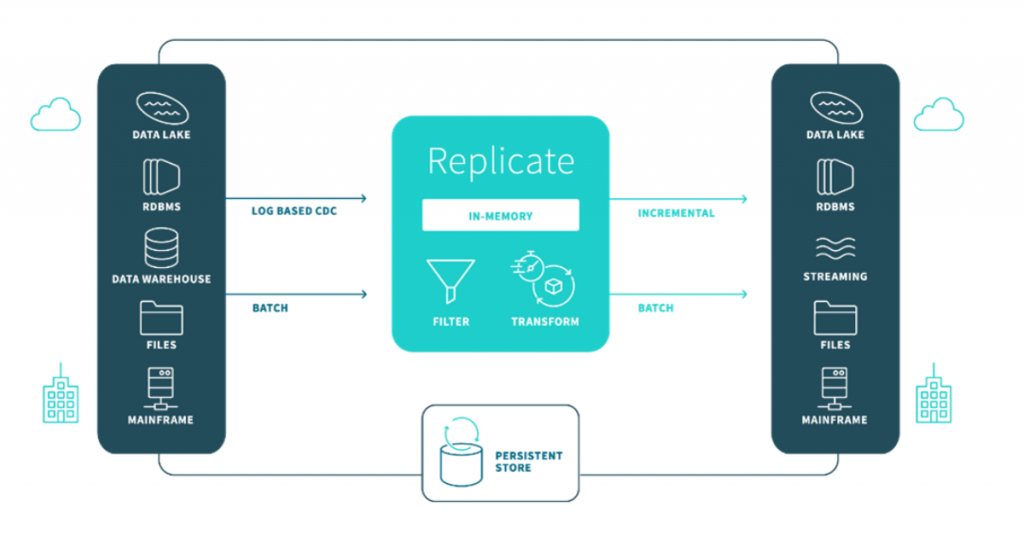
Wann sollten Sie sich für Qlik Replicate™ entscheiden?
Wenn Sie Daten in die Cloud migrieren, Aktualisierungen für einen Stream bereitstellen oder einen Data Lake kontinuierlich mit Daten versorgen wollen, verwenden Sie Qlik Replicate mit seiner intuitiven grafischen Benutzeroberfläche, der automatischen Datenerfassung und -replikation sowie den leistungsfähigen Echtzeit-Updates durch Change Data Capture (CDC). Wenn Sie die Zeit, Kosten und Risiken von Data-Warehouse-Projekten spürbar verringern möchten.
Im Überblick
- Intuitive grafische Benutzeroberfläche für automatische Datenreplikation
- Bereitstellen von Echtzeit-Streamingdaten und Echtzeit-Updates durch Change Data Capture (CDC)
- Unterstützung für eine Vielzahl von Unternehmens-Datenquellen und Zielplattformen
- Zentrale Überwachung und Steuerung mit Zeitplanung, Benachrichtigungen und Alarmfunktionen.
- Übertragung großer Datenmengen aus unzähligen Quellen in Big-Data-Plattformen wird vereinfacht.
- Automatisches Generieren von Ziel-Schemata auf Basis der Quellmetadaten.
- Nutzen paralleler Threads zur effizienten Verarbeitung von Big-Data-Ladevorgängen.
- Verwenden der CDC-Prozesse (Change Data Capture), um den Aufwand für die Bereitstellung von Echtzeitanalysen zu minimieren.
Integrationsaufgaben / Anwendungsfälle:
- Replizieren von Änderungen an einer MySQL-Datenbank in eine PostgreSQL-Datenbank.
- Streamen von Datenänderungen nach Apache Kafka.
- Bereitstellen von Teradata-Daten für Apache Hadoop.
Im Überblick
- Intuitive und geführte Workflows
- Data Warehouses werden schnell konzipiert, erstellt, geladen, aktualisiert.
- Der automatisch generierte ETL-Code spart Zeit, Kosten und Risiken
- Die Effizienz von BI-Projekten mit Best Practices und Vorlagen wird erhöht.
- Die Abhängigkeit von Technikspezia-listen wird reduziert.
IT-Teams aufgepasst
- Daten werden schnell und einfach geladen und synchronisiert.
- Die Quell-Feeds werden mittels Change Data Capture (CDC) geladen. Die Bewirtschaftung erfolgt via Scheduler.
- „Automatische E/R-Modellierung und automatische Datenmodellierung nach der Data-Vault-Methode.“
- Datenmodelle können erstellt oder importiert und anschließend manuell angepasst werden.
- Data-Warehouse – und ETL-Generierung werden beschleunigt. Der ETL-Code zum Befüllen und Laden von Data Warehouses wird automatisch erzeugt.
- Data Marts werden ohne manuellen Programmieraufwand implementiert. Dazu stehen mehrere Data-Mart-Typen zur Verfügung, z.B. transaktional, aggregiert oder zustandsorientiert.
Im Überblick
- Data Catalog kann EIN Ort sein, an dem alle Mitarbeiter:innen Daten in Ihrem Unternehmen finden, verstehen und verwalten.
- Data Catalog stellt Daten transparent, vertrauenswürdig und analysebereit zur Verfügung.
- Enthält Funktionen zur Bestimmung der Datenherkunft zur Optimierung Ihrer Analysepipeline:
- Begriffe werden logisch nach Business-Kontext, der gemeinsam genutzten Terminologien eingeordnet.
- Korrektheit und Konsistenz der Daten wird gesichert.
Vorteile: - Mithilfe des Self-Service BI-Ansatzes mehr Einblicke und Erkenntnisse gewinnen.
- Die Planung von Migrationen wird erleichtert durch schnelle Überprüfung des Speicherorts und Lebenszyklus von Datenquellen.
- Datenüberschneidung vorgreifen und erkennen wenn doppelte Datennutzung in Qlik Sense, Tableau und PowerBI vorkommt.
- Data Governance ermöglichen.
- Mit Impact-Analyse ermitteln, welche Datenbanken, Apps, Dateien und Links von der Änderung eines Feldwerts betroffen sind.
- Die übergreifende Auswertung von hunderten, sogar tausenden QVD-Datendateien ermöglichen und managen.
Sie migrieren Daten in die Cloud?
Stellen Aktualisierungen für einen Stream bereit?
Oder laden Sie kontinuierlich einen Data Lake?
Dann lesen Sie direkt hier weiter. Lassen Sie sich Ihre Testversion zu Datenreplikation, Echtzeitstreaming (CDC) in der Cloud bereitstellen.
Werden Sie Teil von Qlik Data Integration
- Wie schnell heutige Data Warehouses aufgebaut werden mithilfe Qlik Repliclate
- Warum automatisierte-Data Warehouse-Lösungen agiler, kostengünstiger und flexibler sind als herkömmliche Lösungen.
- Wie trotz der hohen verfügbaren Datenmengen in Zukunft weit mehr Analysemöglichkeiten und Analyseinitiativen bereitstehen, die Unternehmen wirklich voranbringen.
- Daten-Drehscheibe zur Datenhaltung an einem zentralen Ort.
- Neue DWH-Datenbanken in der Cloud
- DWH-Modellierung sowie automatische Tabellen- und ETL-Generierung.
- Real-Time-Daten-Streaming großer unstrukturierter Datenmengen. (CDC)

46 Minuten warum und wie heutige Data Warehouses eingerichtet werden, wie das Comeback zu erklären ist.
Qlik Replicate Look & Feel
Möchten Sie Qlik Replicate live erleben, dann sprechen Sie uns gezielt auf ein individuelles Webinar an:
